1. CUBE() : 소계와 전체 합계까지 출력하는 함수
CUBE() 함수는 ROLLUP() 함수와 같이 각 소계도 출력하고 추가로 전체 총계까지 출력합니다.
대신 추가로 전체합계까지 보여주기 때문에 집계 컬럼들이 가질 수 있는 모든 경우에 대하여 소계를 생성해야 하므로 ROLLUP() 함수에 비해 시스템 리소스를 더 사용합니다.
CUBE() 는 집계컬럼들의 모든 경우에 대한 소계를 구하므로 순서가 바뀌어도 데이터는 같습니다.
만약 보서별 평균 급여와 사원 수, 직급별 평균 급여와 사원 수, 부서와 직급별 평균 급여와 사원 수, 전체 평균 월 급여와 사원수를 구하시오 라는 문제가 주어진다면
1. 부서별 평균 급여와 사원 수
2. 직급별 평균 급여와 사원 수
3. 부서와 직급별 평균 급여와 사원 수
4. 전체 평균 월 급여와 사원 수
이렇게 4가지로 분류가 되는데 CUBE()를 사용하지 않고 일반 GROUP BY절을 사용하면 총 4개의 SELECT절이 필요합니다.
SELECT DEPTNO, NULL JOB, ROUND(NVL(AVG(SAL), 1)) AVG_SAL, COUNT(*) CNT_EMP
FROM EMP
GROUP BY DEPTNO
UNION ALL
SELECT NULL DEPTNO, JOB, ROUND(NVL(AVG(SAL), 1)) AVG_SAL, COUNT(*) CNT_EMP
FROM EMP
GROUP BY JOB
UNION ALL
SELECT DEPTNO, JOB, ROUND(NVL(AVG(SAL), 1)) AVG_SAL, COUNT(*) CNT_EMP
FROM EMP
GROUP BY DEPTNO , JOB
UNION ALL
SELECT NULL DEPTNO, NULL JOB, ROUND(NVL(AVG(SAL), 1)) AVG_SAL, COUNT(*) CNT_EMP
FROM EMP
ORDER BY DEPTNO , JOB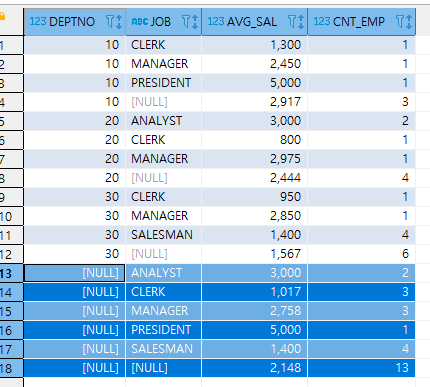
위 그림에서 파란색으로 칠해진 부분 전체가 ROLLUP()에서 없엇던 전체 총계 부분입니다.
이렇게 4개의 SQL로 작성해서 UNION ALL로 연결할 경우 쿼리의 수행시간이 오래 걸립니다.
EMP 테이블을 총 4번이나 읽어야 하기 떄문이죠.
이번에는 동일한 결과를 얻기 위해 CUBE() 함수를 사용해보겠습니다.
참고로 CUBE() 함수에 지정된 컬럼들의 수를 N일때 2*N승 소계가 생성이 됩니다.
SELECT DEPTNO, JOB, ROUND(NVL(AVG(SAL), 1)) AVG_SAL, COUNT(*) CNT_EMP
FROM EMP
GROUP BY CUBE (DEPTNO, JOB)
ORDER BY DEPTNO , JOB ;CUBE() 함수를 사용하면 SQL이 훨씬 간결해지고 EMP 테이블도 1번만 읽기 떄문에 리소스 관리나 속도측면에서도 좋습니다.
실무에서 실제로 대량의 데이터를 집계할 때도 아주 많이 사용됩니다.
'데이터베이스 > Oracle SQL' 카테고리의 다른 글
| 오라클 SQL과 PL/SQL ( PIVOT / 달력만들기 ) (0) | 2021.08.03 |
|---|---|
| 오라클 SQL과 PL/SQL ( GROUPING SETS / LISTAGG ) (0) | 2021.08.02 |
| 오라클 SQL과 PL/SQL ( ROLLUP 함수 / 분석함수 - 1 ) (0) | 2021.07.31 |
| 오라클 SQL과 PL/SQL ( GROUP BY / HAVING ) (0) | 2021.07.29 |
| 오라클 SQL과 PL/SQL ( 복수행 함수(그룹 함수) ) (0) | 2021.07.28 |